近日,由智谱与华为联合研发并开源的多模态图像生成模型GLM-Image,登顶Hugging Face平台Trending榜第一,打破长期以来国外模型在开源榜首的垄断局面。
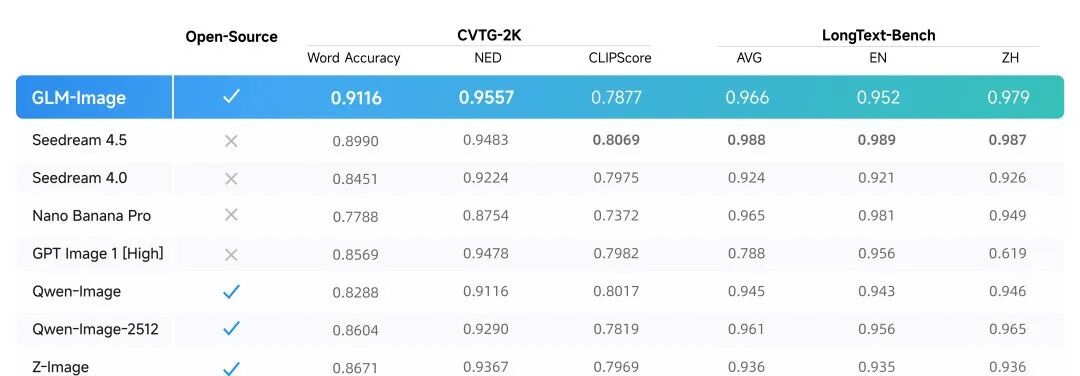
并且GLM-Image一出道就拿下了CVTG-2K(复杂视觉文字生成)和LongText-Bench(长文本渲染)双榜单的第一:
再细分来看,在CVTG-2K中,GLM-Image凭借0.9116的Word Accuracy(文字准确率)和0.9557的NED(归一化编辑距离)拿下双料第一,表明生成的文字在准确性上做到了高度一致。
以及LongText-Bench中的中文、英文或平均分数,都位列开源模型中的第一。
除此之外,再划个重点:
用GLM-Image的API生成图片,现在一张图只要一毛钱(0.1元)!
国产芯+国产模型,这次真的赢麻了。
值得一提的是,该模型基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架,完成从数据到训练的全流程,是首个在国产芯片上完成全程训练的SOTA多模态模型。
而这背后,是智谱与华为“软硬协同”的深度合作,更是国产AI全产业链突破的缩影。
天下苦AI生图不识字已经久矣。
以前让AI画个海报,画面虽然美如画,但文字却是乱如麻:不是缺笔少划,就是自创火星文。
这次GLM-Image最大的卖点,可以说就是能读懂且写对。
那么接下来,我们就来给GLM-Image一些刁钻的难题,考验考验它的能力。
首先是咱们熟悉的“小红书风”。
这种图片不仅要求审美在线,最关键的是标题要大、要醒目,还得和画面完美融合。
我们扔给GLM-Image一段描述比较笼统的描述,让它先来自我发挥一下:
Prompt:生成一张小红书封面,图文并茂,表达泰国旅游最全攻略,要有人物和风景,有趣的设计。
感觉GLM-Image已然get到了小红书封面的奥义,鲜艳的配色、醒目的文字,还有逼真的人物,一下子就让人想点进去了解一番。
还有小红书上比较流行的科普详解图,GLM-Image可以根据智谱官方推文直接生成亮点内容图解:
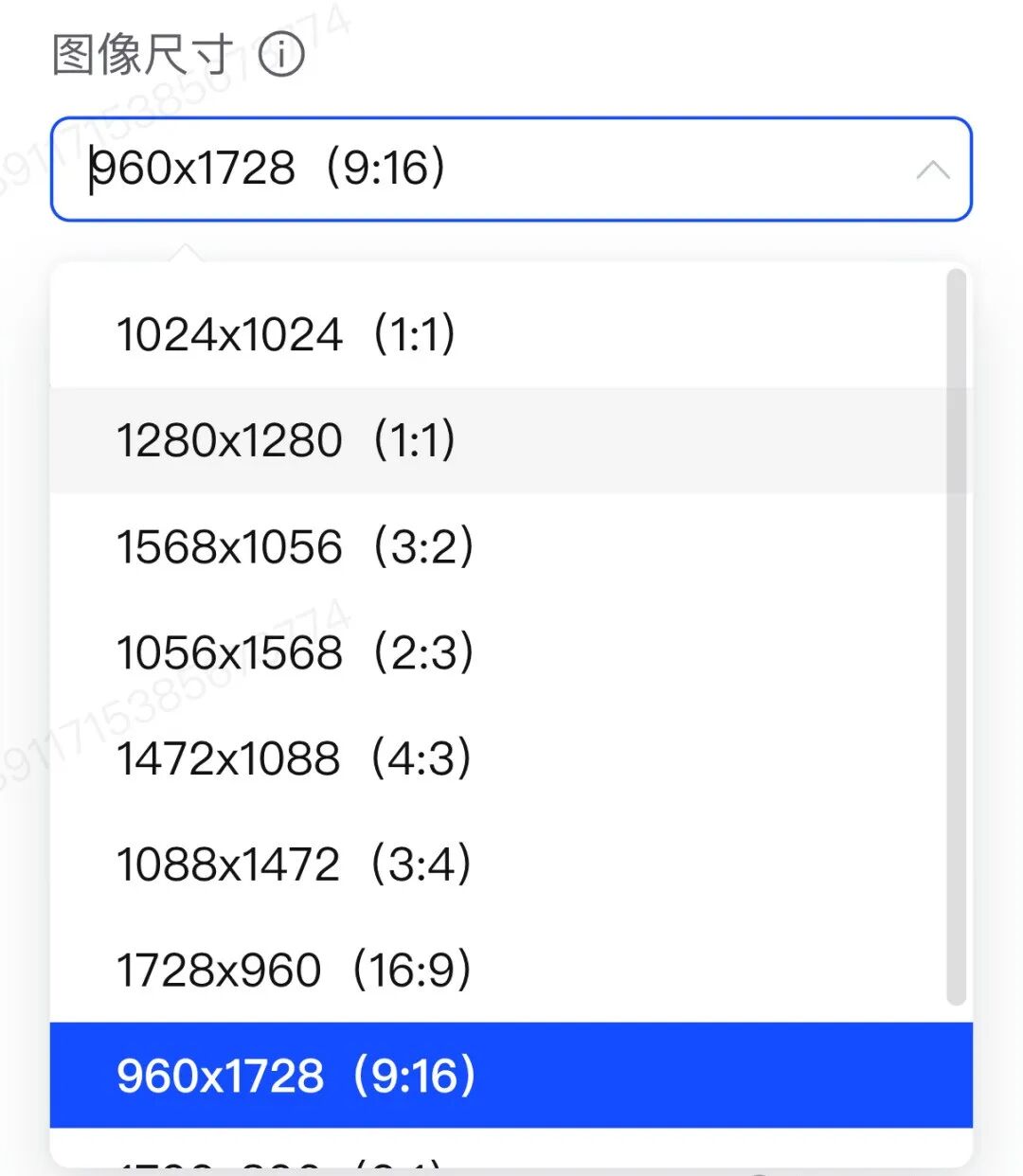
而且GLM-Image原生支持1024x1024至2048x2048的任意比例输出。智谱开放平台体验中心提供了10个尺寸的选项,可以适配各种类型的社交媒体平台。
假如你现在想要做一张有艺术感的商业广告大片,那么只要把你的想法转成Prompt即可,例如:
Prompt:大师级摄影,获奖作品,东方禅意,神秘氛围。中心构图,极致负空间留白,一位沉静内省的男性背影,戴浅色宽檐帽,处于绝对静止剪影状态。中景:浓雾弥漫充满全部画面。双重曝光,人物透明叠加于中景,透明晕染重叠,重叠处露出黄昏都市,暖金色暮光逆侧光,建筑轮廓与霓虹因慢门化作动态模糊、拖曳的暖黄色光轨。光影:黑柔滤镜,轮廓光勾勒帽檐肩线,面部阴影中有微妙的深灰至灰渐变,强烈明暗对比。色调:低饱和度暖调(浅棕、暖黄、灰绿,阴影泛青灰),富士怀旧负片胶片质感。后期:空气透视,朦胧诗意,印象派氛围。视觉张力,虚实结合,情绪氛围摄影,电影帧叙事。标语:“流光过隙,我自静观。” 半透明标题“SILENCE”嵌入雾中。
真实性,也是考验图片生成能力的重要因素。
接下来,我们就让GLM-Image生成几张真实人物的照片:
Prompt:一位男模特,行走于都市天台,风衣下摆被大风扬起,动态模糊,大场景,强透视,低角度仰拍,胶片粗颗粒质感,黑金色调,前卫艺术美学,力量感,高级感,时尚大片视角,8K,大师杰作。
像极了在现实生活中拍出来的男模特。
智谱相关负责人介绍,GLM-Image采用自主创新的“自回归+扩散解码器”混合架构,实现图像生成与语言模型的联合,是面向以Nano Banana Pro为代表的新一代“认知型生成”技术范式的一次重要探索。
基于上述架构创新,该模型在CVTG-2K(复杂视觉文本生成)和LongText-Bench(长文本渲染)榜单获得开源第一。据了解,模型尤其擅长文字密集生成任务。CVTG-2K榜单核心考察模型在图像中同时生成多处文字的准确性,在多区域文字生成准确率上,GLM-Image的成绩位列开源模型第一;LongText-Bench(长文本渲染)榜单则考察模型渲染长文本、多行文字的准确性,覆盖招牌、海报、PPT、对话框等8种文字密集场景,GLM-Image的成绩位列开源模型第一。
此外,模型兼具高性价比与速度优化,在API调用模式下,生成一张图片仅需0.1元,速度优化版本也即将更新。
“GLM-Image是我们对国产计算生态的一次深度探索与验证。其自回归结构基座从早期的数据预处理到最终的大规模预训练,全流程均在昇腾Atlas 800T A2设备上完成。”上述负责人透露。
该负责人介绍,华为搭建的“国产算力底座”是关键支撑。不同于以往多数AI模型依赖国外芯片训练,GLM-Image从数据预处理到大规模训练,全程跑在华为昇腾Atlas 800T A2芯片和昇思MindSpore框架上。正是这套全自主的“硬件+框架”组合,解决了AI训练“卡脖子”的核心问题,让模型训练摆脱了对国外芯片的依赖,更验证了在国产全栈算力底座上训练前沿模型的可行性。
业内人士表示,从更长远看,GLM-Image登顶不是偶然,而是国产AI全产业链协同的必然结果。这种全链条能力,不仅能让国内中小企业以更低成本用上AI工具,更能推动国产AI技术走向全球,有望改写过去“国外定标准、国内跟节奏”的产业格局。如今,GLM-Image的开源地址已在GitHub和Hugging Face平台同步开放,全球开发者都能免费使用这套“国产方案”。
在图像生成这个领域,大家似乎都习惯了盯着国外的Flux、Midjourney、Ideogram看。每当国外发布一个新模型,大家就感叹一句“差距又拉大了”。
但GLM-Image的出现,是一次有力的回应,主要可以从三个方面来看:
打破垄断:它证明了SOTA级的模型效果,完全可以在国产芯片上实现。这给国内其他的AI开发者打了一针强心剂。
开源普惠:不仅仅是模型开源,它还把这种“自回归+扩散”的新架构思路分享了出来。对于想要研究下一代生图技术的人来说,这就是最好的教科书。
极致性价比:API调用价格极其亲民,生成一张图的成本甚至不到一毛钱。这对于想要接入AI生图能力的中小企业、开发者来说,简直是降维打击。
Nano Banana固然很好,但那毕竟是别人家的,还是闭源的那种。
但现在,我们有了自己的Open Banana——GLM-Image:开源的、国产算力训练的、懂中文、会写汉字的。
无论你是想做个不重样的小红书博主,还是想搞个自动生成海报的创业项目,或者单纯就是想体验一下国产之光的生图能力,GLM-Image都值得你上手一试。