最近,来自LMSYS Org(UC伯克利主导)的研究人员又搞了个大新闻——大语言模型版排位赛!
顾名思义,「LLM排位赛」就是让一群大语言模型随机进行battle,并根据它们的Elo得分进行排名。然后,我们就能一眼看出,某个聊天机器人到底是「嘴强王者」还是「最强王者」。
划重点:团队还计划把国内和国外的这些「闭源」模型都搞进来,是骡子是马溜溜就知道了!(GPT-3.5现在就已经在匿名竞技场里了)
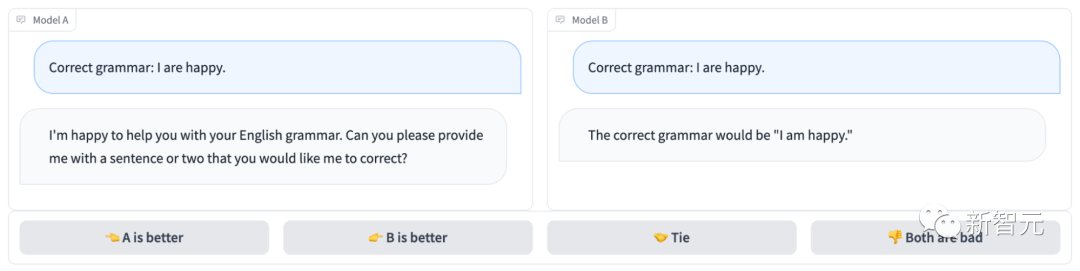
匿名聊天机器人竞技场长下面这样:
很明显,模型B回答正确,拿下这局;而模型A连题都没读懂……
项目地址:https://arena.lmsys.org/
在当前的排行榜中,130亿参数的Vicuna以1169分稳居第一,同样130亿参数的Koala位列第二,LAION的Open Assistant排在第三。
清华提出的ChatGLM,虽然只有60亿参数,但依然冲进了前五,只比130亿参数的Alpaca落后了23分。
相比之下,Meta原版的LLaMa只排到了第八(倒数第二),而Stability AI的StableLM则获得了唯一的800+分,排名倒数第一。
团队表示,之后不仅会定期更新排位赛榜单,而且还会优化算法和机制,并根据不同的任务类型提供更加细化的排名。

目前,所有的评估代码以及数据分析均已公布。

